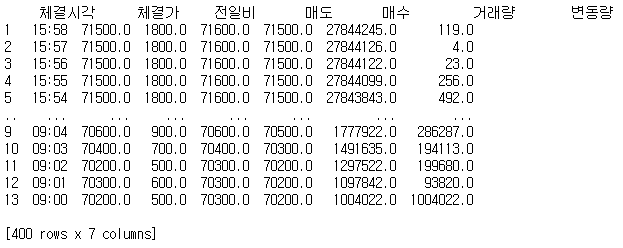
뒤에 &page=40 이런 식으로 파라미터가 붙는 것을 알 수 있고 마지막 페이지는 40임을 알게 되었습니다.
이제 마지막 페이지를 구하는 파이썬 코드를 구현해 보도록 하겠습니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = 'https://finance.naver.com/item/sise_time.nhn?code=005930&thistime=20201204161047'
with urlopen(url) as doc:
html = BeautifulSoup(doc, 'lxml')
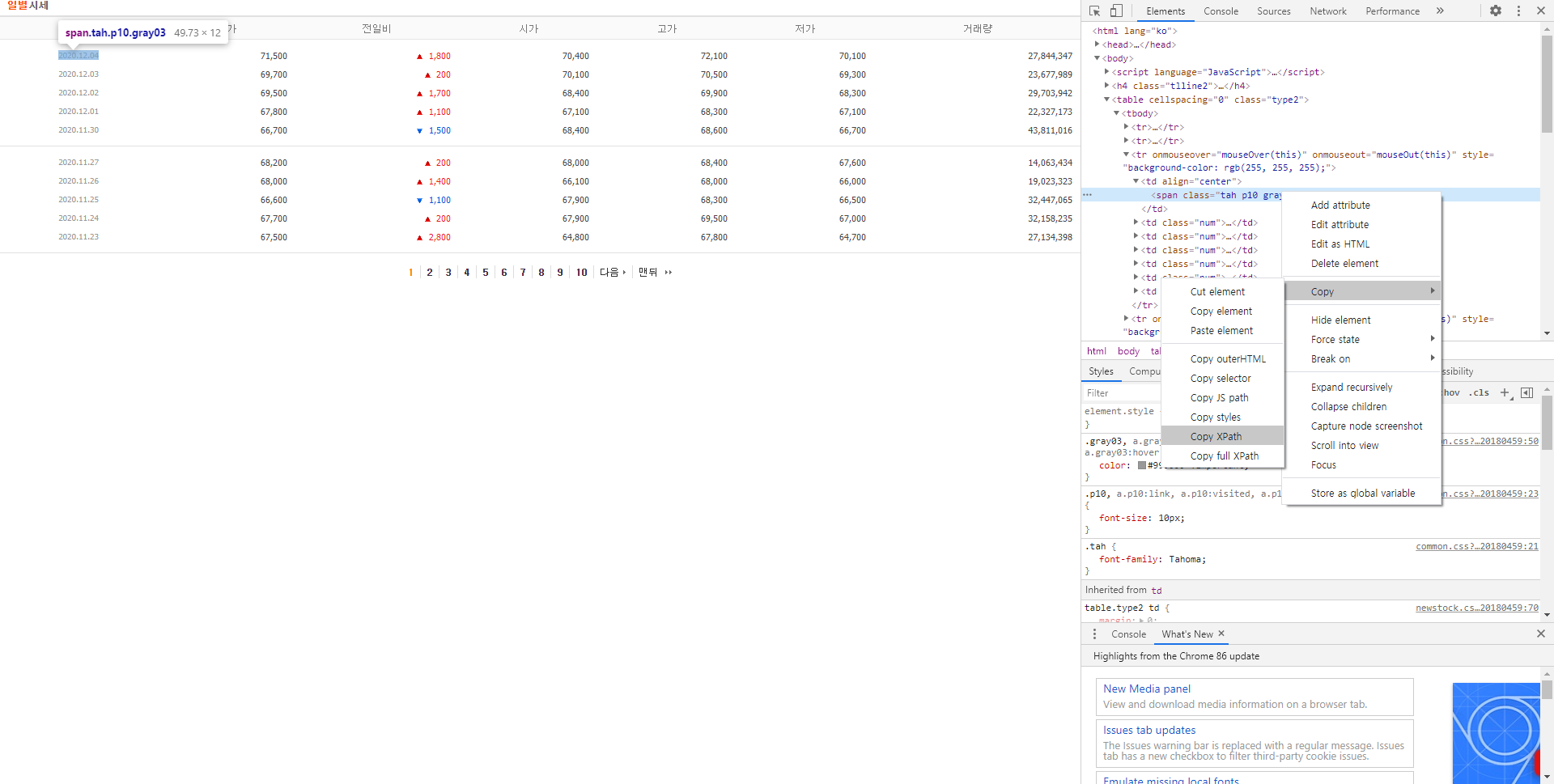
pgrr = html.find('td', class_='pgRR') # (1)
s = str(pgrr.a['href']).split('=') # (2)
last_page = s[-1] # (3)
print(last_page)
(1) 'pgRR' 클래스를 가지는 td 태그를 찾아서 pgrr에 담습니다.
(2) pgrr 아래 a 링크 주소를 '=' 기준으로 split 합니다. a 링크 주소는 /item/sise_time.nhn?code=005930&thistime=20201204161047&page=40인데 '=' 기준으로 split하면 s에는 ['/item/sise_time.nhn?code', '005930&thistime', '20201204161047&page', '40']이 될 것입니다.
(3) 리스트 데이터의 마지막 데이터를 가져옵니다.
이제 마지막 페이지까지 루프를 돌아 전체 페이지를 읽어오는 로직을 구현해 봅시다.
파이썬 코드는 다음과 같습니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://finance.naver.com/item/sise_time.nhn?code=005930&thistime=20201204161047'
df = pd.DataFrame()
with urlopen(url) as doc:
html = BeautifulSoup(doc, 'lxml')
pgrr = html.find('td', class_='pgRR')
s = str(pgrr.a['href']).split('=')
last_page = s[-1]
for page in range(1, int(last_page)+1):
page_url = '{}&page={}'.format(url, page) # (1)
df = df.append(pd.read_html(page_url, header=0)[0]) # (2)
df = df.dropna()
print(df)
(1) page 파라미터에 1부터 last_page 까지 for문을 돌아 url을 갱신합니다.